
This set of slides sketches out the implementation of Hell, in technical detail. I do tend to switch between the slides, old code, and the present code, so bear with me. It's more about the ideas. If you want to see a complete implementation, the complete implementation of Hell is one file, which you can look through easily.

There are a few limits on the language; no imports, no
polymorphism (poly types) i.e. no declaration is ever
inferred with a forall a. in it. Poly types are
awesome, but they make the implementation harder, and are a
form of abstraction that you might not need in a scripting
language. I don't need them in my case, YMMV.
No imports: instead, all names that usually come under a
package name like async
become Async.race, List.map,
etc. All identifiers are explicitly qualified except
lambda parameters: \x -> x -- not qualified.
Recursion is completely ruled out, but fix
works fine, so you still have it as a primitive
function. It's just not something you can produce
yourself.
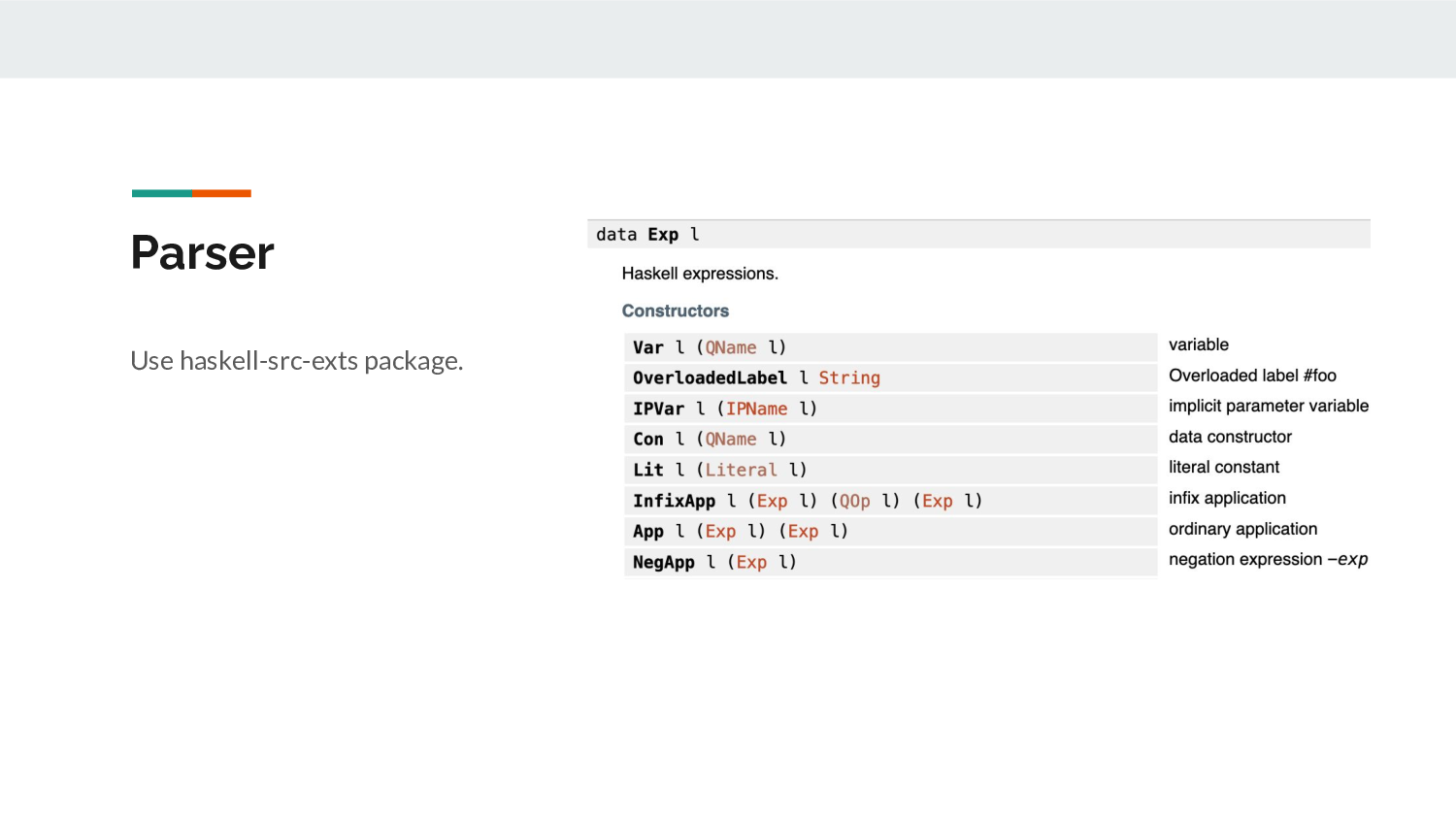
Rather than bothering to implement a parser, I used haskell-src-exts. That package isn't really maintained anymore, but I'm kind of used to it now, and GHC's parser is a bit too wordy for me.
Re-using a parser is usually wise, parsing layout in Haskell is fiddly and I just wanted something that works as I'm used to.
The next step is to desugar this syntax into something
smaller. do-notation becomes
nested >>= calls, etc.

Parsing is the beginning of the pipeline. For this project, a primary concern was to make the evaluator as lean as possible, and, ideally, total and complete. With this in mind, I started at the interpreter and worked backwards from there. What does a trivial but total evaluator look like in Haskell?

Here's a basic one. It's called "higher-order abstract syntax" because you've got syntax productions that take functions as arguments. Rather than carrying an environment around, like in, e.g. How to Write a (Lisp) Interpreter (in Python), you store a function as a real function. When you pass an environment around, you tend to have a lookup function that could throw an error if you got your evaluator wrong.
This evaluator is total and won't crash. This is really neat and tidy. The only downside really is that it's opaque. It's hard to work with functions, because you can't look inside them once you've made them. You also can't smooth out the wrinkles inside them, at least, as far as I'm aware. I've heard of cunning approaches to do so, but some things are best left alone.

I encountered another approach while perusing Oleg Kiselyov's Typed Tagless Final Interpreters paper and he dropped in this example like it was the most normal thing in the world. I'm not sure where Oleg got this from.

This evaluator is not higher order. It features environment lookup and the evaluator carries around an environment. But there's something clever here: that lookup will always succeed.
The environment is a simple stack of tuples. When evaluating a lambda, simply wrap the environment in another tuple with the argument being passed.
Variables are church numerals: 0 is VZ, 1
is VS VZ, 2 is VS (VS VZ), etc.
It's
a de
Bruijn index that is statically typed. It means "how
far up the stack do you go?" Lookup simply walks both the
church numeral and the environment until the zero case
(VZ) is reached, and then what's there in the
stack is returned.
The way to make this total and guaranteed to be correct is via the
env type parameter that both the Exp type and the Var type
share.
It took me a few readings to believe that this actually works. It's
beautiful.

Hell's core AST and evaluator are almost identical, with a couple adjustments.
- Oleg's example hard-codes Bool just for demonstration
purposes. Hell's AST has
Litinstead, which can produce anya. All primitive functions e.g.List.mapor e.g. literals like123are kept in there. -
In the zero case for
Var, Hell keeps a function as a final accessor function. This lets us easily pull out a tuple slot from a function argument, e.g.\(x,y) -> xbecomes, conceptually,\xy -> fst x. This could later possibly be used for e.g.\X{x,y} -> x.
(The TypeRep is gone now. It was just
handy for debugging at the time.)
Otherwise it's exactly the same, and in the year since I wrote the first version of Hell, this AST and the evaluator function have not changed at all. For me, this is an achievement. It's lovely to keep it so simple.
Working backwards, an immediate question arises: how do you produce this quite strongly-typed AST from a completely untyped text input?
Stephanie Weirich published a single file type checker implementation that addresses this problem neatly. It blew my mind that this was possible in Haskell so cleanly.

The type signature essentially goes
from UTerm (an untyped term) to a
typed Term which has the type of the term as
a parameter.

The UTerm AST is a simple model of an AST that
you might parse from a string. Note: there is
a UType explicit type attached to the lambda
that tells us what type the parameter is; your parser
would parse e.g. \(x::Bool) -> .. into this.
In this example, UType is simply an "untyped" (meaning
in the meta language doesn't have attached type
information) type, which is either Bool or Bool ->
Bool etc.
There's a familiar pattern here. Just like the evaluator
seen above in Oleg's paper, the Var type
gives us a variable reference whose scope is statically
determined. Note the Term (g,a) in
the Lam constructor; the g
corresponds to the one in Var g t.
The type-checkers job is to not only check that the types match up, but to build up this well-typed variable referencing.

As for the Ty itself, it's a type-indexed equivalent of
the UType type. The meta language (or host language) is
using its own type system to mirror what's in the object
language (or guest language). In the types as well as in
term-level code.
Here's how the UType becomes a Ty
t. A handy existential is needed that'll be used in
the type-checker called
ExType that just holds the result of the type-check.
With these types in place, the type checker for UType ->
ExType practically writes itself.

Turning to type-checking terms, type-checking an if requires an
extra trick which is to compare that two types are equal and get a
proof that they are so. The
cmpTy function starts with an a and b and by
pattern-matching and aided by a handy GADT called Equal which
essentially makes first class the ability to get both a
value-level and type-level proof that a ~ b. There
are shorter ways to do this, of course, but this is how it's done
in this small example file.
Finally, it can produce a convenient type
called Typed that just couples up a thing with its
type, as both the thing and the ty are indexed by the same
thing. It locks in that relationship.

To both type-check and also scope-check a variable, there's need
for an environment to keep track of those things in a typed lookup
table while doing type-checking. It's like the stack earlier, but
has a String in it to help build the correct de Bruijn index
level based on the name. The more the TyEnv is walked, the more
nested Var becomes.
Type-checking a UVar then just becomes a lookup. (Imagine that
the error calls are instead returning Left, but they were
omitted for simplicity of the implementation.)
Type-checking a lambda is more complicated and where the meat is:
- First, get a
Ty aof the lambda's parameter type. - Type-check the body with the parameter in scope.
- Construct an
a -> btype withArrfor the binder and the body. - Finally, the
Lamhas enough type proofs in scope to be constructed.

Comparatively, type-checking applications is easy. It's
just a quick check that the function being applied is of
type a -> b and then that the argument is of type a.

In review, this is the whole type checker. The example
main shows how one might construct a basic untyped
UTerm and then type-check it. The initial argument to
tc is, unsurprisingly, Nil for the environment.
That's it! Isn't that beautiful!
Evaluating this AST is exactly the same as evaluating as seen above. This shows that you can type-check an untyped AST and then evaluate it with a total evaluator. Noice!

According to Three questions of language design, it's not long before the question of how to do equality and ordering comes up. How do you compare strings, integers, etc? And how do you do things like sets and maps that require some kind of ordering.
Haskell already has good answers for this:
type-classes. For Hell, I didn't want to have to
support full type-classes and all attendant
features, but I equally didn't want to give up on
including Map and Set or
even List.lookup, and end up with Int.eq,
Text.eq, etc.
Luckily I discovered that Eitan Chatav had posted somewhere on reddit an example of exactly what I wanted to do, which was to infer based on known types type-class dictionaries for a few specific type-classes.
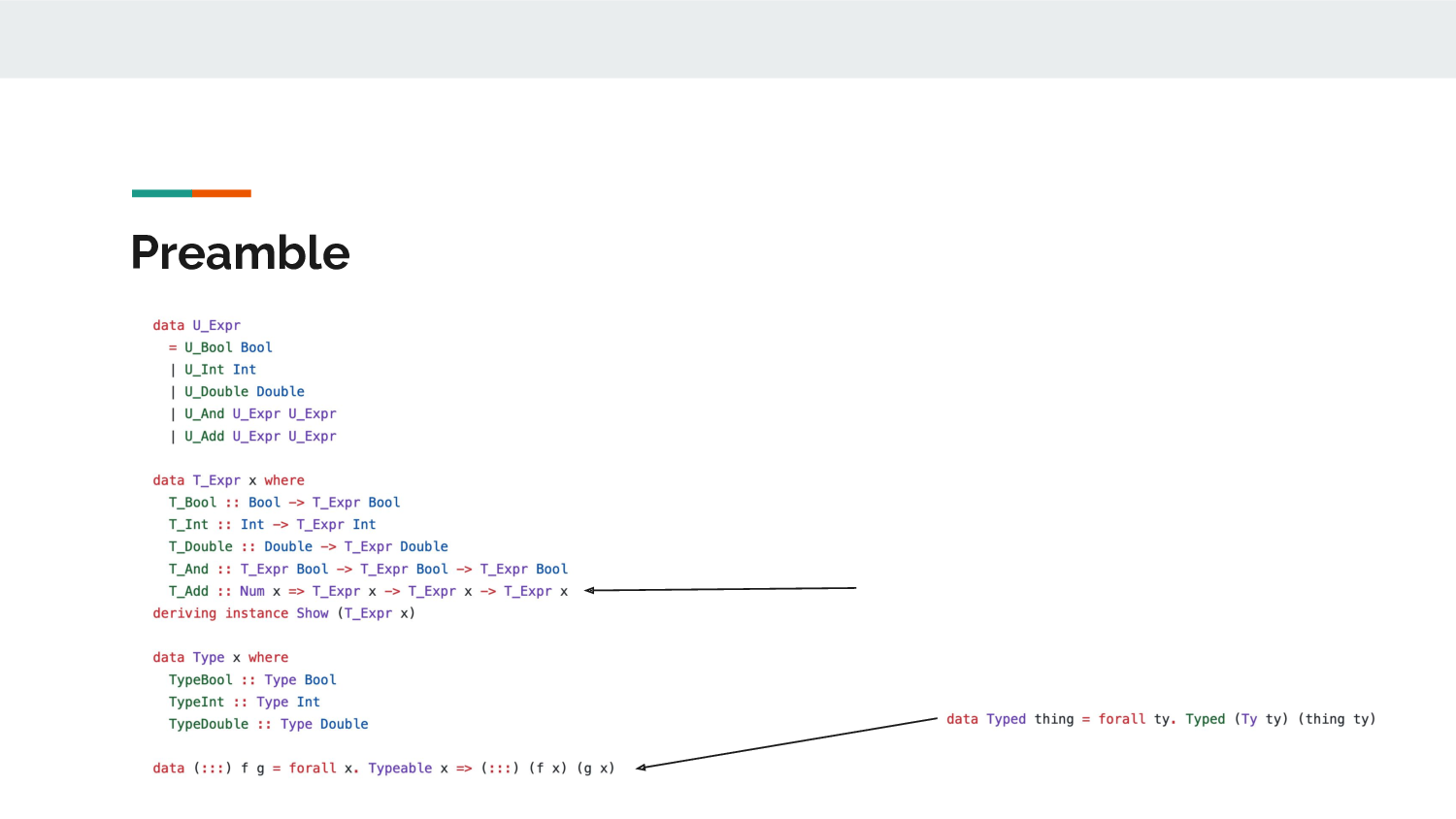
In the term type, an actual class constraint can be added
in there! Eitan's terms, types and Ty-equivalent are
slightly different, but are otherwise identical.

The trick here is simply to dispatch on the well-typed
type-indexed GADT of Type and in that case one can
"capture" the type-class instance dictionary and then the
T_Add constructor is able to use that for its class
constraint!
This makes sense after you've seen it, but it blew my mind when I first saw it.
This is not how how I did it in Hell, obviously;
the Term type has no class constraints in it
as seen above. But it gave me the key first step that I
was able to evolve to what I needed.

The Ty type defined earlier is fine, and the Equal
utility, but it turns out Stephanie later made the
Type.Reflection abstraction which replaces Ty a with
TypeRep a, and provides equality, too. It can
also deal with any Haskell type, of any kind.

As a reminder, I showed that the TypeRep (a ::
Type) is used in the Term type instead
of the Ty a used in Stephanie's demo file
that was much older.
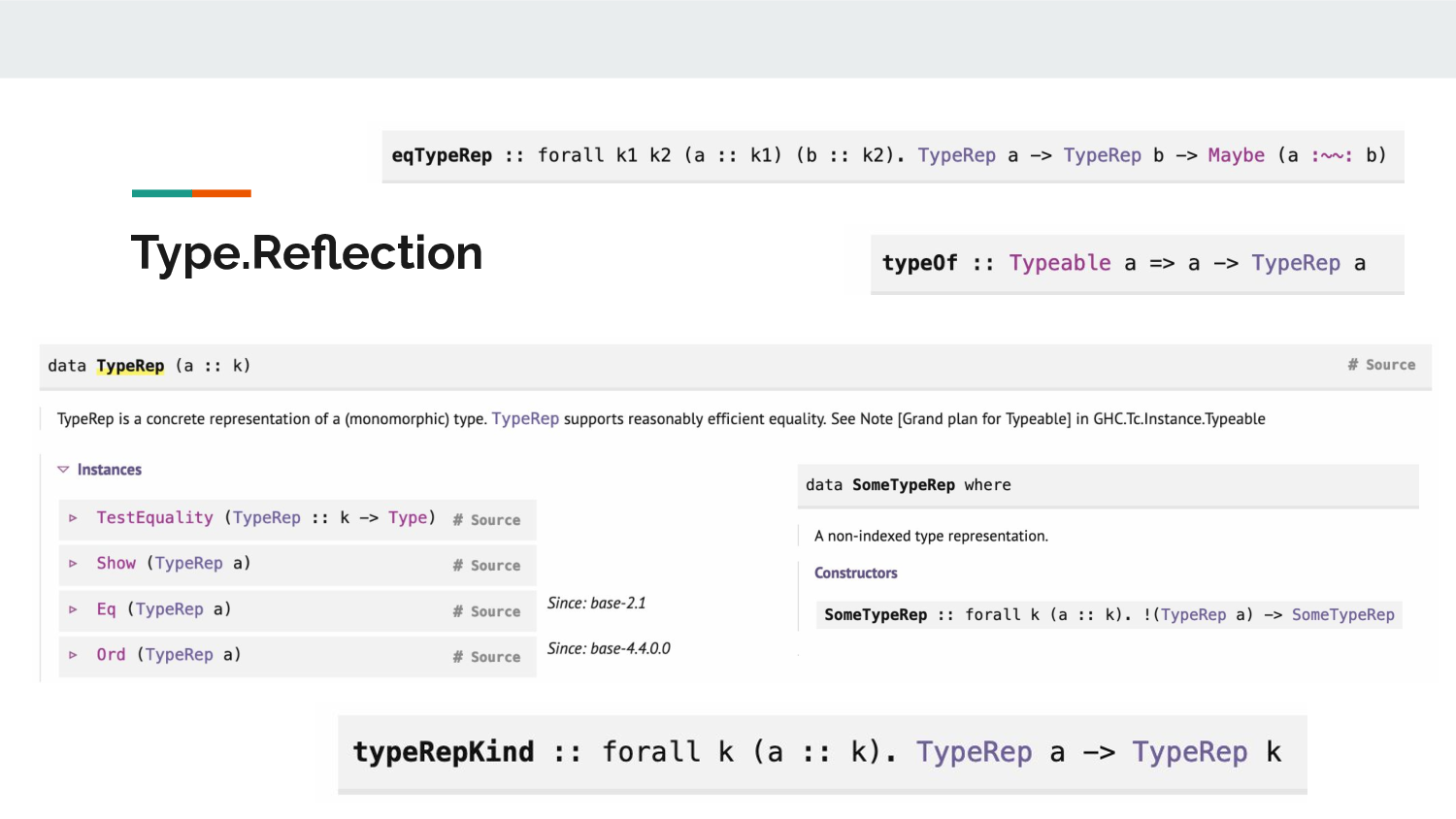
From Type.Reflection you've got a TypeRep a type, you
can get a TypeRep a from any type that's an instance of
Typeable, and can compare types for equality.
Because any kind of type can be worked with, you often
have to check that the kind is the one you expect before
working with the type, so typeRepKind comes in handy
there, too.

Here's an example of how I wrote a trivial function to apply some unknown one type to another which is used in the inferer later on. There's a much better implementation later down the page, but this is fairly easy to read.

Up to here I've covered a parser which yields
HSE.Exp (the haskell-src-exts type) and I've described
the Term AST that a type-checker is able to produce and
an evaluator able to interpret. What's missing is the
"untyped" term type, UTerm. Additionally, I
want type inference, which is a step that should sit
somewhere between parsing and final type-checking.

Desugaring in Hell goes from HSE.Exp HSE.SrcSpanInfo
(haskell-src-exts) to UTerm ().

The UTerm type now takes an extra parameter t in which
I'll put SomeTypeRep - so it's similar to earlier, but
I can now put other choices of type annotation in there.
I use a handy type SomeStarType which just constrains
the kind of the a in the TypeRep a to be Type
(previously * in GHC); the type of regular
values. You can see this concept in action in toStarType
seen in the slide.

I tried for a while with Hell to avoid type inference, because it can complicate everything. I don't need no stinkin' type inference! ... But after trying to write a real script in Hell, I realised that writing out the types of everything gets tedious really quickly.

When doing type inference, instead of working with
SomeTypeRep as seen above, which has no concept
of variables, I've defined IRep
(inference type rep) for that. It has a type
parameter for the representation of variables. While doing
inference, it's going to be a little newtype wrapper
around numbers called IMetaVar. When inference is
finished, it'll be Void, ready for converting to
SomeTypeRep.

inferExp's job is to make a UTerm () into a UTerm
SomeTypeRep -- if it can't do that, then there's either a
type mismatch, an ambiguous type
(zonking
failed), or an infinite type. You can see in the
implementation of zonk that it's just making sure that
there are no type variables anymore.
After that,
toSomeTypeRep just converts
our IRep tree into
a SomeTypeRep. That can still fail if our
type inferer has a bug. Unlikely, but it's not ruled out.

A typical split in a type inferer is "elaborate, unify"
which means first walk the AST and simply generate
equality constraints like f ~ a -> b
and a ~ [Char] and b ~ Int, and
then the second part is to unify these constraints to get
e.g. [Char] -> Int. It's a nice clean
separation. Many industrial compilers will do these two
phases in the same phase in the name of efficiency and the
ability to generate new constraints on the fly, but I
prefer the clean separation.

fromSomeStarType produces an IRep void for the case
that I know the type of something ahead of time, i.e. my
primitives (Int.plus, etc.).
On the right is a sample of elaborations of different parts of the AST. There isn't really anything in here that's out of the ordinary or that I'm excited to go into detail about.
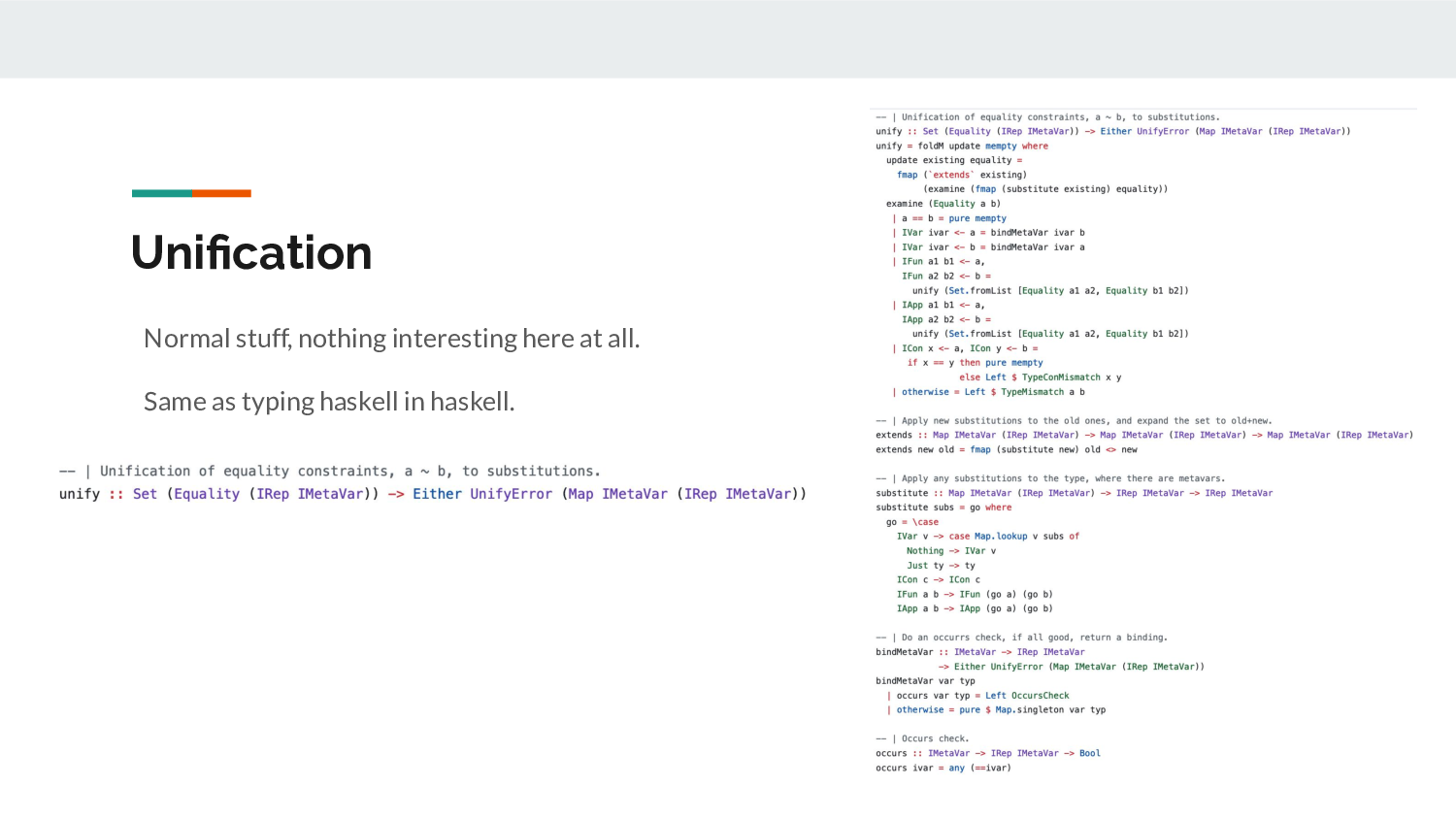
For unification, there's nothing new in here, either; it's
very by the book. Given a set of equality constraints,
generate a set of substitutions (replace these variables
with these types). Afterwards, one can apply those
substitutions to any type. In our case, that's all
the t in UTerm.
You can use off-the-shelf unification libraries like unification-fd or implement a mutable algorithm for extra speed, or use union-find, but this one fits on a page and does the job presently.

Initially the AST had this for primitive terms:
ConBool :: Bool -> Term g Bool ConString :: String -> Term g String
Which is fine if you want to enumerate every single type of value you want to be able to work with. I didn't want to do that. There's a way to make that shorter:
Lit :: a -> Term g a ... ULit (forall g. Typed (Term g))
And then when you want to express e.g. True in the
object language, you can just write a handy function like
this that'll go straight from any Typeable into a
Typed:
lit :: Type.Reflection.Typeable a => a -> UTerm lit l = ULit (Typed (Type.Reflection.typeOf l) (Lit l))
The type checker case is a no-op:
tc (ULit lit) _env = lit
And then simply lit True will work.
So far so good, but what about polymorphic things? Like
the function id? My solution was to make a newtype
around a function, and that function accepted the type as
an argument, just like in system F:
newtype Forall = Forall (forall (a :: Type) g. TypeRep a -> Typed (Term g)) ... UForall SomeStarType Forall
And in UTerm, carry a type and the forall together. So
e.g. id would be represented like this:
id_ :: Forall id_ = Forall (\a -> Typed (Type.Reflection.Fun a a) (Lit id))
I can then instantiate id_ with whatever
type I want, such as Bool:
UForall (SomeStarType (Type.Reflection.typeRep @Bool)) id_
It would merely be the type inferer's job to provide
these type reps to the UForall, with the checker just
applying the function:
tc (UForall (SomeStarType typeRep) (Forall f)) _env =
f typeRep
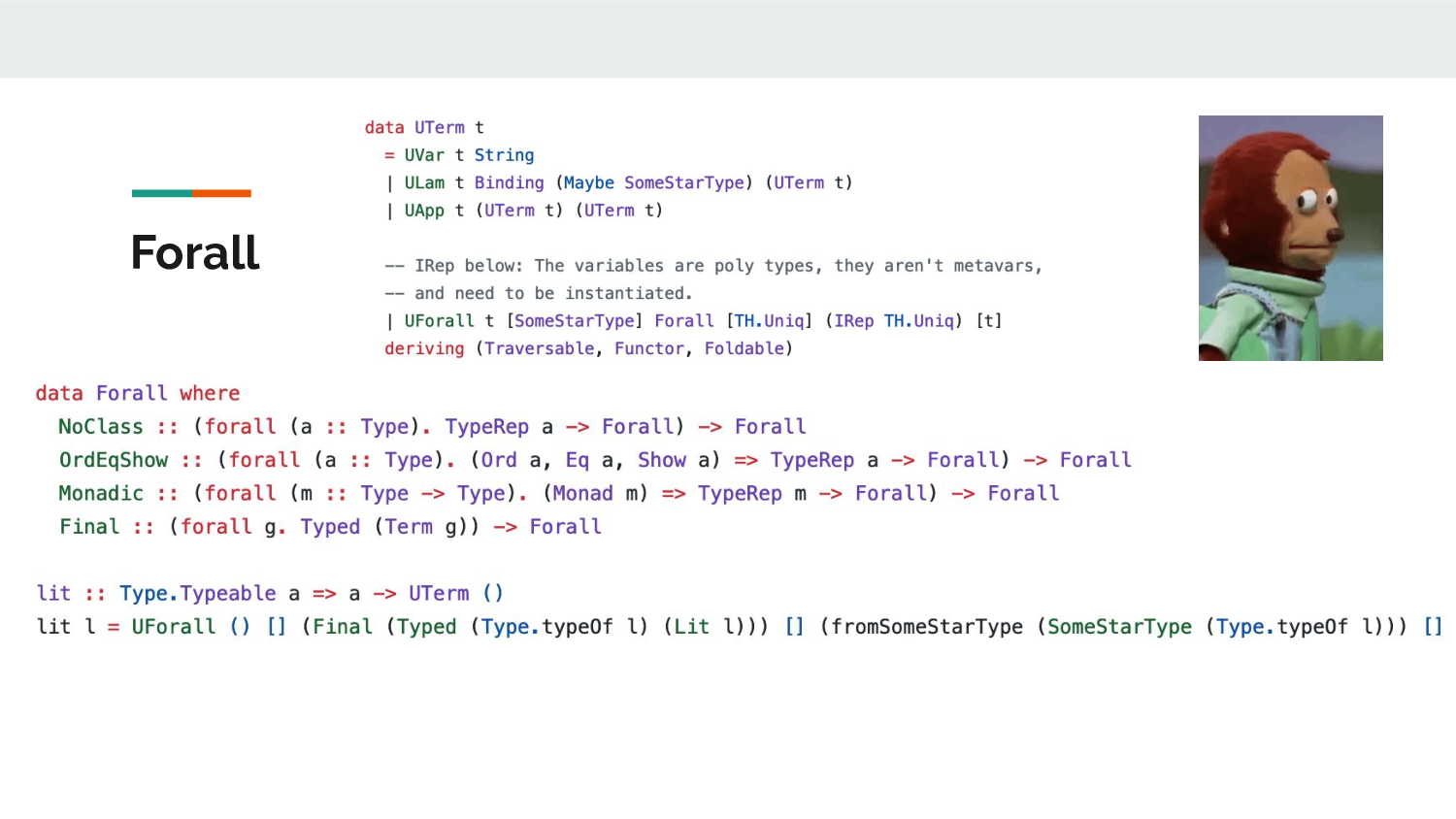
Since that initial discovery and implementing type
inference, I changed Forall to be a GADT which represents a
chain, so that it can be for example: Eq a => Monad m => ...
Type inference adds a load of extra metadata to the
UForall constructor, but the core idea is the
same.

The example of id hasn't changed very much, although here I'm
using the TypeRep pattern to be able to bring the a
type variable in directly.
In fact, I've since
enabled any kind of type, so it becomes a full SomeTypeRep in
UForall, in order to support records (which I'll show
later) and their Symbol field names.
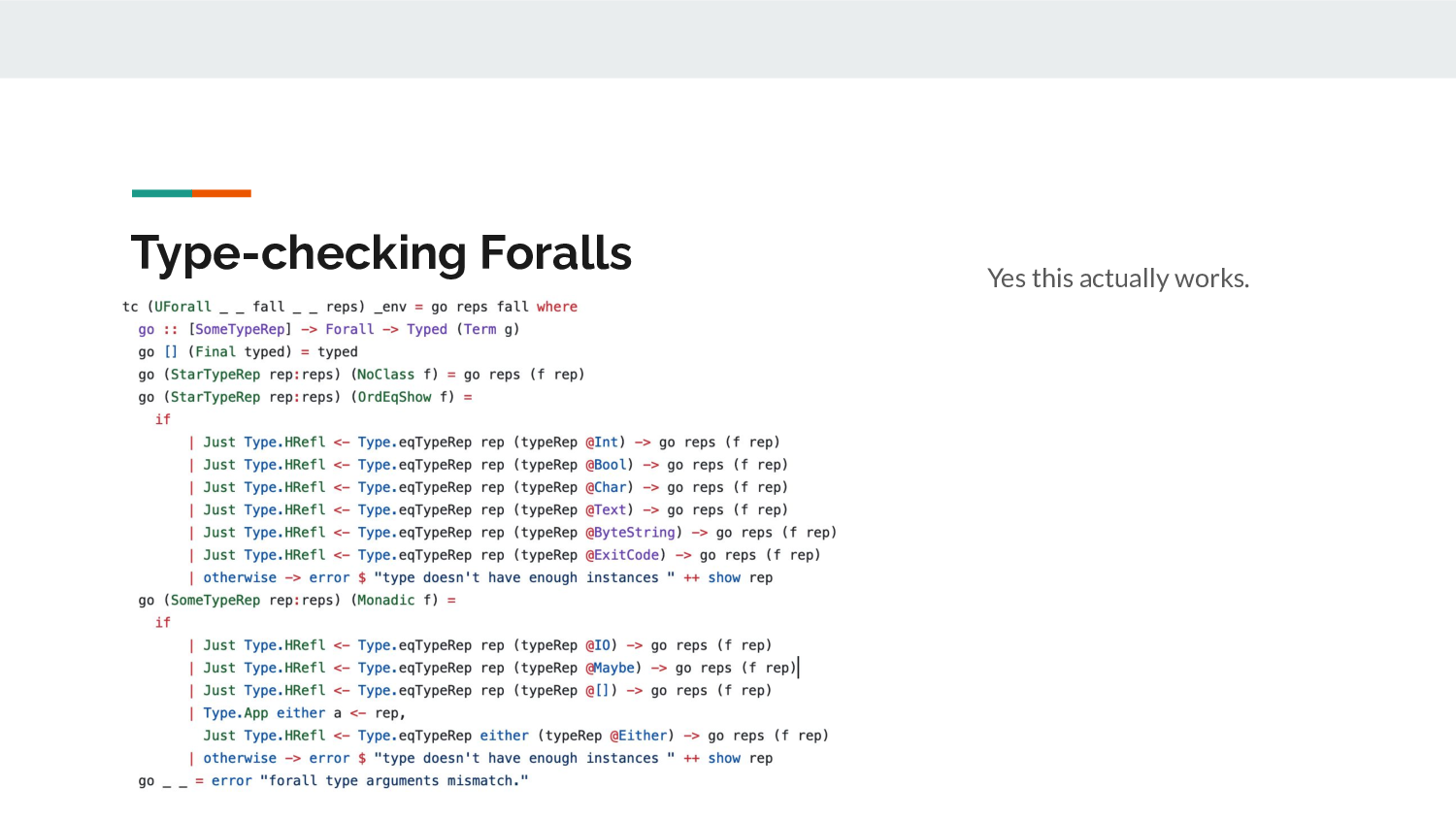
When type-checking these foralls, it's just a loop that successively
applies poly type arguments to functions that accept them. In the case
of type-classes like OrdEqShow, I use Eitan's trick of proving that
the type is e.g. one of Int, Bool etc. known types that support
Ord, Eq and Show and then simply continue applying the
arguments. Yes, this works, and yes, I was surprised. Even
higher-order kinded stuff like Monad had no trouble.

Elaboration of foralls was straight-forward and this hasn't changed
since I made these slides. All I'm doing is generating a
meta-variable for each poly type in the forall, so a, b,
etc. Then I transform the type signature like forall a. a -> a that
is originally IRep TH.Uniq (template-haskell's way of
generating unique references) to IRep IMetaVar. Now I
can use it in the unifier.
The types variable represents any manually specified types like
id @Int, in which case we can emit an equality constraint on
the first poly type as a ~ Int.
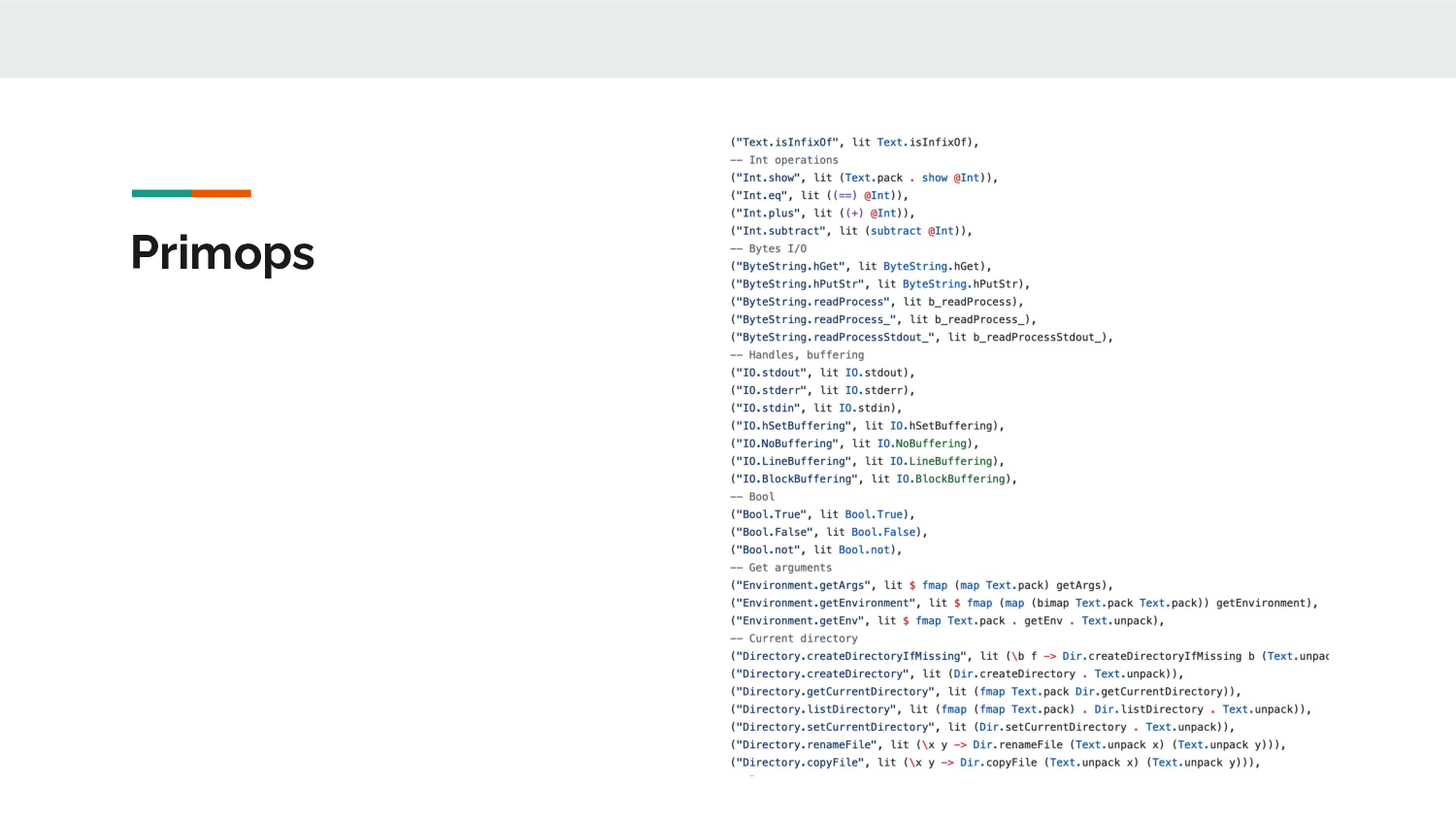
Primops that aren't polymorphic can all be defined via lit,
like this.
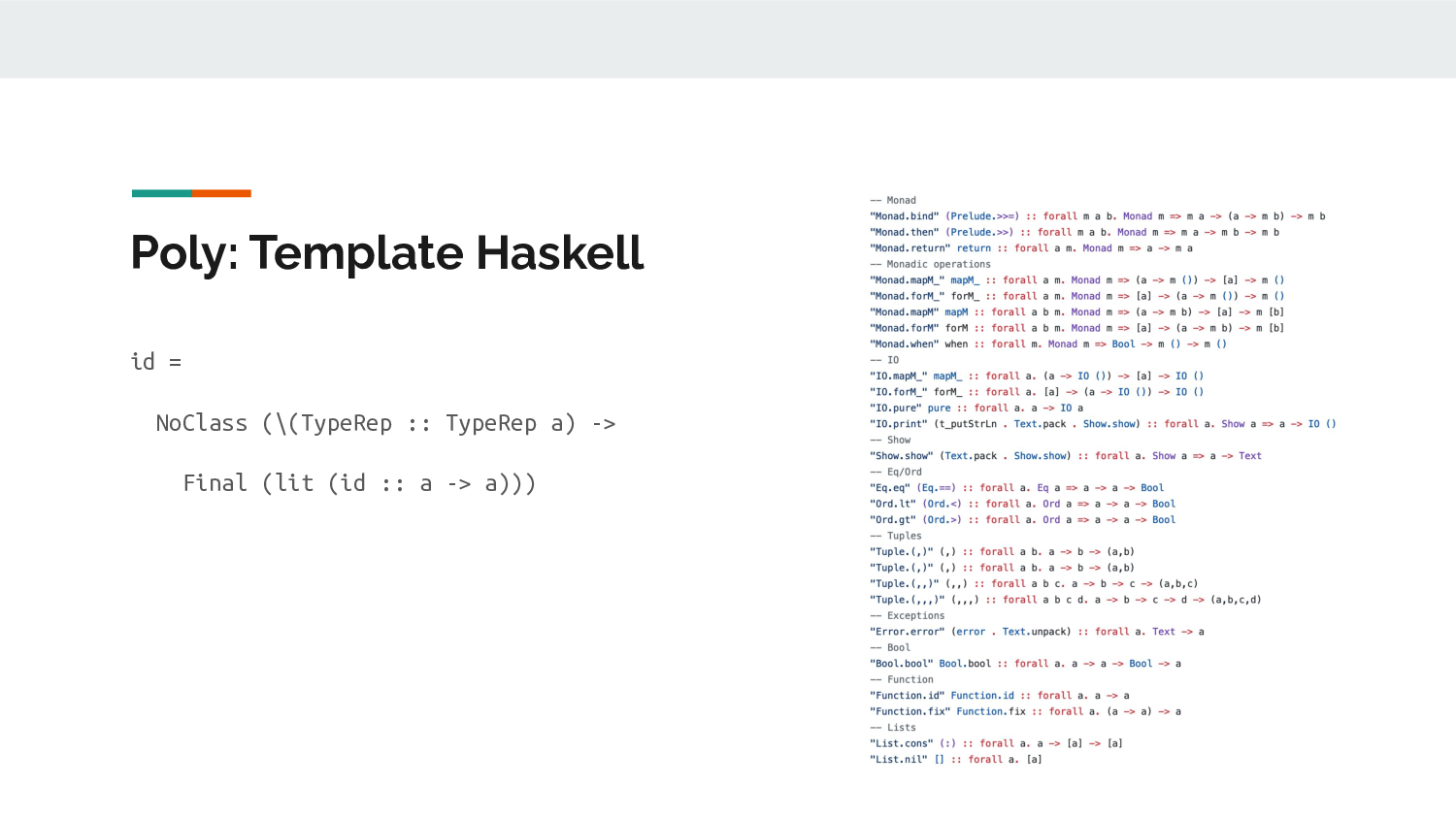
As you saw above, writing out polymorphic prims
like id is a bit boring and long. So i wrote some
template-haskell to generate them for me based on a list like
this. I won't go into the implementation because you can imagine
it. Just generate the boilerplate.

The nice thing about using TypeRep is I didn't have to write
much when listing out the supported types. I just specify their
name and use typeRep. It doesn't matter what kind they
are, which is quite nice.

I'd originally intended to eventually add records to the language, just for ferry data around within a script. But I took some months before settling on an approach.
The hard part about supporting records that are type-safe in both the meta language and the object language is mostly about lookup. A fairly obvious thing is that I'd need some kind of anonymous records implementation, but it wasn't clear for a while about how to do safe lookup.
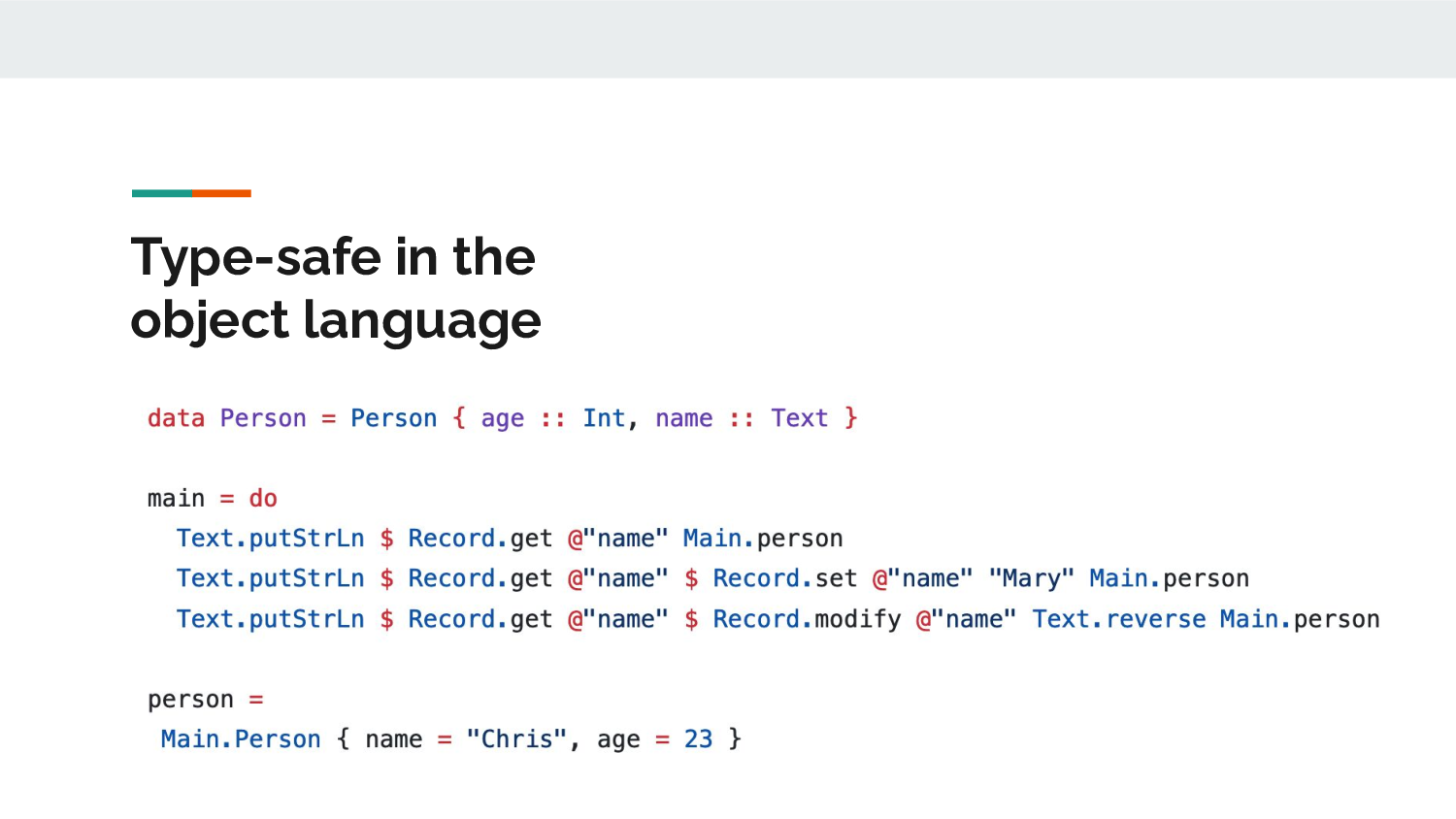
In the language, declaring records is regular Haskell. Accessing records is done via getters and setters, rather than pattern-matching or dot-notation. I would like dot-notation, but that requires work on the parser, so I'll return to it in the future.
The constructor must be qualified like all other names.
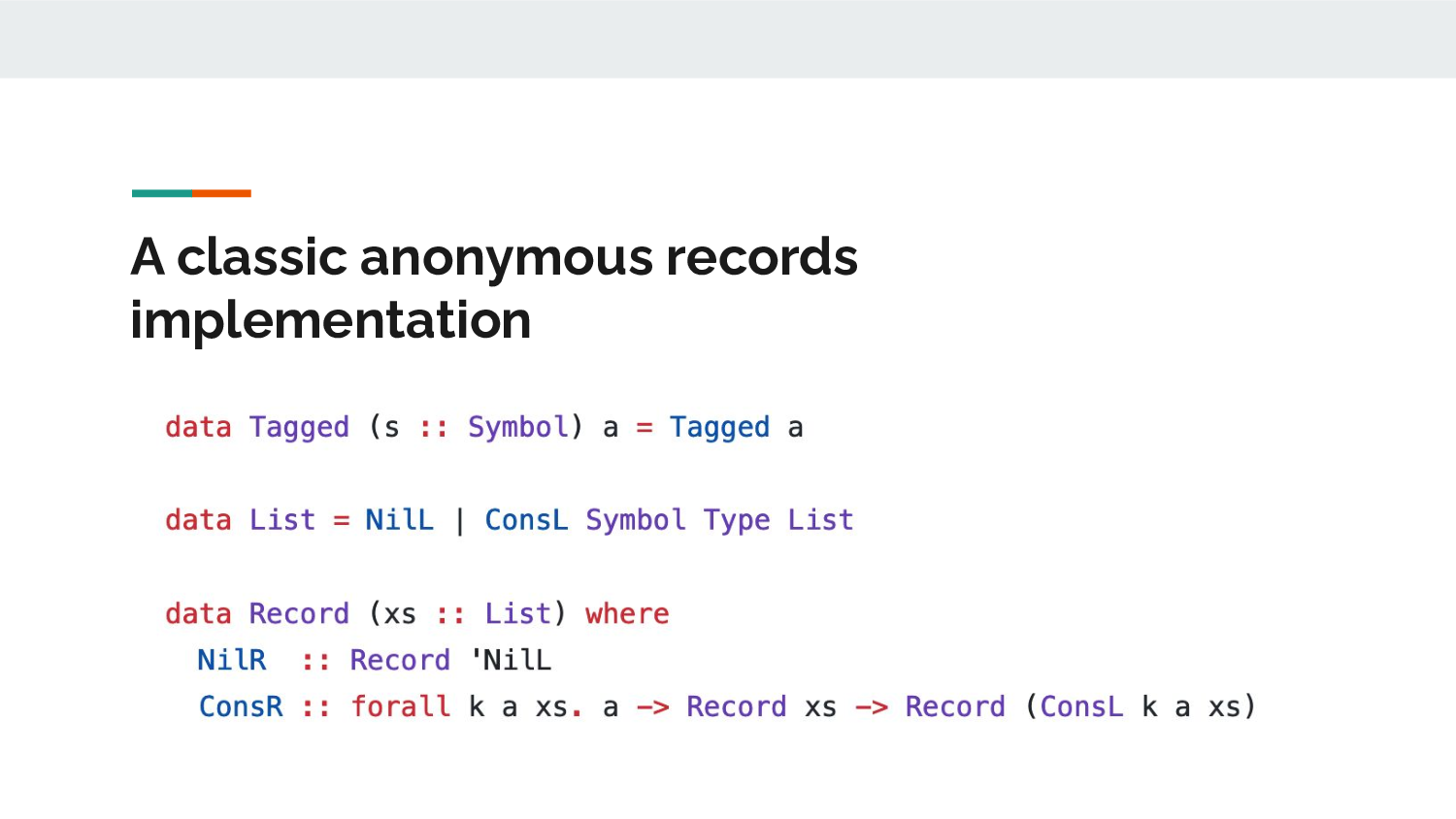
I used a classic GADT-driven implementation of records,
with a type-level list consisting of a Symbol (which is
why I had to support any SomeTypeRep in the type
inferer) and a type. There isn't anything particularly
special about Record and List, unless you've never
seen HList or anonymous records before.
One thing that is a little new is simply that the types,
like Person above, are simply Tagged "Main.Person"
(ConsR .. ) which avoids accidentally permitting two
structurally equivalent types from unifying; the tag keeps
it nominal. Handily, this does permit me to
support true anonymous records down the line, though at
the moment, I don't want to stray much from "regular"
Haskell if I can help it.

As I said above, having to support SomeTypeRep motivated
me to write a much better implementation of applyTypes
which works for any kind of types. And it turns out to be
shorter. Although it took a couple of tries to get it
right. Unlike, say, Idris or Agda, this kind of type magic
in Haskell has bad error messages and not a lot of helpful
explanation to guide you along.

I really did not want to have to write some kind of
HashMap-based record implementation with error calls in
it. That would harsh my vibe.
Fortunately, I figured out another way using
Type.Reflection again. I'm really happy with this
result; I was able to generate accessors (get, set,
modify) for a record that is type-safe in the meta
language and also the object language, with no
partiality. At type-checking time in Hell's type-checker,
it simply returns a Maybe ... function, and
if you get a Just, it compiles; if not, no
compile.
The implementation I did not expect to work at all. First
I unwrap the Tagged. Then I have a
loop, go, which walks the
record's type, and while walking the type,
accumulates a function capable of walking a
record's value. If all the types match up and it
can find the field with the right name and type, at the
end you'll get an accessor function. If not, you get
Nothing. Good day, sir!
A few notes follow about some things that have been desugared.
I will note that Hell desugars everything before type-checking, and inlines everything, all in one step to get one giant expression to type check. That's not normal; usually you type check and then desugar. But it does mean I don't have to implement System F. It's just plain old simply typed lambda calculus with a few built-in primitive type constructors.

This slide shows that record expressions really are just
rewritten to applications of Tagged "x" (ConsR @"a"
.. NilR). It all happens before type-checking happens.

do-notation follows the usual Haskell approach; it's
desugared into a series of >>= and >>. I've later
adjusted this to rewrite HSE.Exp -> HSE.Exp and then
call the desugarer on that expression, rather than going
straight from do-notation to a UTerm, just to make
scope-checking better.

While working on this I've been thinking of Hell's compiler as "front-loaded". All the heavy lifting happens in the desugarer and the inferer. The type checker is on the order of 100 lines and the evaluator is about 10 lines. I really quite like this style of compiler.

The main entry point that executes scripts looks like
this. Parse it, desugar it, infer it, type check it, and
then finally, check that main is of
type IO (). If so, simply run the function!
That's it.

End of slides. Hopefully this will actually be legible, both for myself and anyone with niche interest enough to be reading through it.
Future work probably includes at
least adding
locations to types, adding sum types, and adding a
case syntax.